

Hay un tipo de problema que los equipos de marketing raramente priorizan: el que no produce ruido inmediato. No hay una alerta en rojo, no hay un CPC que explote de la noche a la mañana. La captura de datos propios opera exactamente en esa zona silenciosa. Se asume resuelta porque hay plataformas activas, flujos configurados y reportes que llegan cada semana. Pero cuando alguien pregunta quién es realmente dueño de esos datos, la respuesta empieza a desmoronarse.
Tus campañas corren, tus dashboards están llenos y aun así algo no cierra
El presupuesto está ejecutado, las audiencias segmentadas, los reportes de Meta Ads Manager y Google Analytics muestran números que en papel tienen sentido. Y sin embargo, cuando intentas conectar esos datos con lo que pasa en tu CRM o en tu modelo de atribución multi-touch, aparecen huecos que nadie logra explicar con precisión.
No es un problema de volumen de datos. Es un problema de origen. Gran parte del ecosistema de datos que alimenta las decisiones de marketing hoy no viene de fuentes propias. Viene de lo que las plataformas deciden compartir, bajo sus condiciones y con la granularidad que ellas determinan. Eso no es captura de datos propios. Es dependencia operativa disfrazada de estrategia digital.
La diferencia entre tener datos y ser dueño de los datos
Lo que las plataformas te muestran no es tu first party data
Meta, Google y TikTok generan enormes volúmenes de información sobre el comportamiento de tus usuarios. Pero esa información vive en sus sistemas. Lo que llega a tu dashboard es una versión procesada, agregada y filtrada de lo que realmente ocurre.
El first party data real es el que tu empresa recopila directamente a través de sus propios canales: sitio web, CRM, formularios, interacciones por correo y eventos digitales propios. Si esa infraestructura de captura no está activa y bien estructurada, lo que tienes no son datos propios. Son datos prestados.
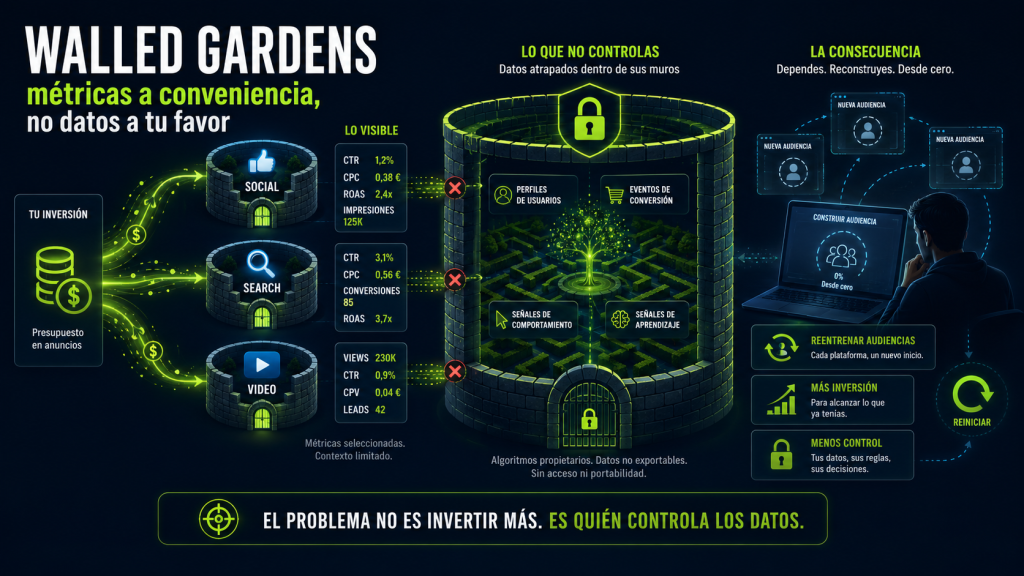
Walled gardens: métricas a conveniencia, no datos a tu favor
El modelo de negocio de las grandes plataformas está construido sobre retener datos. Los walled gardens no son una metáfora. Son una decisión arquitectónica intencional que mantiene la dependencia del anunciante.
Cada vez que una campaña necesita reentrenar audiencias desde cero porque los datos están atrapados en la plataforma, estás pagando el costo real de no tener una estrategia de captura de datos propios activa en paralelo. Según IAB México, la inversión en publicidad digital en el país sigue creciendo. Lo que eso hace más urgente no es invertir más. Es resolver quién controla los datos detrás de esa inversión.
Los síntomas que ya estás viviendo y lo que te están costando
Atribución multi-touch con huecos que ningún reporte te confiesa
Un modelo de atribución multi-touch depende de datos limpios en cada punto de contacto del funnel. Cuando la mayoría de esos puntos están registrados por plataformas con sus propias lógicas de cookieless tracking y sus limitaciones post-iOS 14, el modelo resultante tiene huecos estructurales. El problema no aparece en el reporte. Aparece en las decisiones de presupuesto que se toman con ese reporte, y en el dinero que se asigna mal como consecuencia.
Audiencias que se reconstruyen desde cero en cada campaña
Una base de datos propia bien construida es un activo acumulativo. Cada campaña que lanzas debería enriquecer ese activo. Cuando eso no ocurre, cada iniciativa empieza desde el principio: audiencias lookalike sobre datos de plataforma, segmentaciones que no sobreviven al cambio de algoritmo y un CAC que no baja aunque la marca lleve años en el mercado. El costo no está en una línea del P&L. Está distribuido en ineficiencias que se normalizan.
Personalización acotada por datos que no controlas
Los modelos de Gen AI aplicados a marketing necesitan datos propios de calidad para generar hiperpersonalización real. Sin esa base, se convierten en herramientas potentes aplicadas sobre información incompleta. El resultado es personalización de superficie: relevante en apariencia, genérica en impacto. Y eso se refleja directamente en el LTV.
Las preguntas que tu operación debería poder responder hoy
Antes de hablar de soluciones, hay un ejercicio más útil: hacerse las preguntas correctas. Estas cinco revelan con precisión dónde está el gap real de captura de datos propios en cualquier operación de marketing:
- ¿Qué porcentaje de tus conversiones puedes rastrear sin depender de píxeles de plataforma?
- Si Meta o Google cambian su política de datos mañana, ¿cuánto tiempo tardarías en reconstruir tus audiencias?
- ¿Cuántos puntos de contacto de tu funnel tienen captura de datos propia activa y estructurada?
- ¿Tu modelo de atribución puede operar sin cookies de terceros hoy?
- ¿Cuánto de tu inteligencia de cliente vive en tus sistemas frente a lo que vive en dashboards de plataforma?
Si alguna de estas respuestas genera incomodidad o requiere validación con el equipo antes de responderse, el problema ya está identificado.
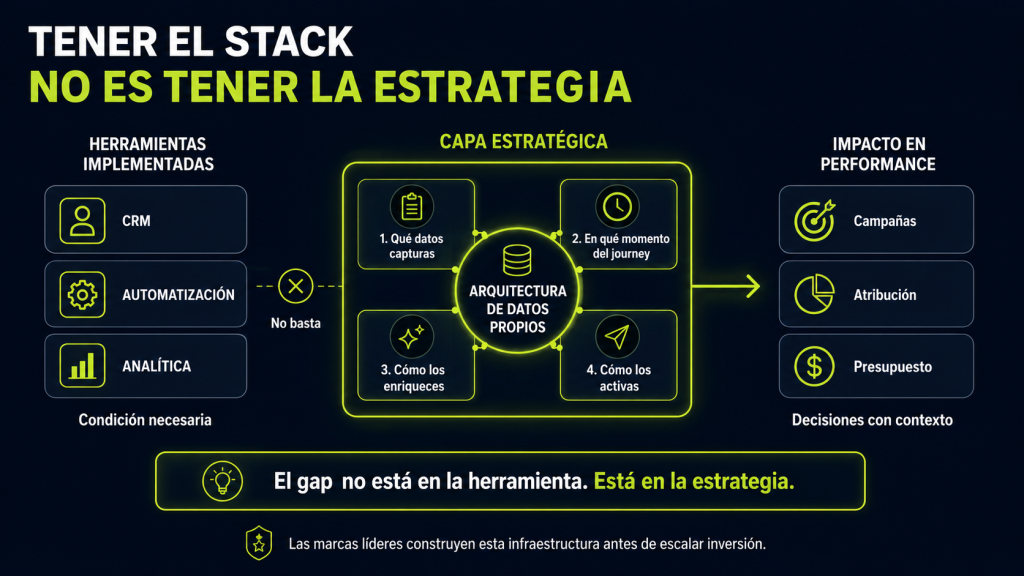
Tener el stack no es tener la estrategia
Tener HubSpot o ActiveCampaign implementado es condición necesaria, no suficiente. Lo que determina si realmente estás capturando datos propios de manera estratégica es la arquitectura detrás de la herramienta: qué datos se recopilan, en qué momento del journey, con qué nivel de enriquecimiento y cómo esos datos se activan en campañas, modelos de atribución y decisiones de presupuesto.
Las marcas que lideran en performance son las que construyeron esa infraestructura de datos propia antes de escalar su inversión en plataformas, no después. El gap no está en la herramienta. Está en la capa estratégica que nadie diseñó formalmente. Esa capa puede reforzarse con una visión de Estrategia Digital y con flujos bien conectados de Marketing Automation.
El diagnóstico es el primer paso, no la implementación
Si las cinco preguntas anteriores generaron más dudas que certezas, el siguiente movimiento no es sumar tecnología. Es hacer un diagnóstico estructurado de tu arquitectura de captura de datos propios: qué está funcionando, qué está generando ruido sin generar inteligencia y qué puntos del funnel están ciegos.
En Prospect Factory trabajamos exactamente desde ahí. No desde la venta de plataformas, sino desde la estrategia que define cómo y dónde capturar datos que realmente te pertenecen. Si quieres saber con precisión dónde está tu gap, contáctanos.
Preguntas frecuentes
¿Cuál es la diferencia entre first party data y zero party data?
El first party data se recopila de forma pasiva a través de interacciones del usuario en canales propios. El zero party data es el que el usuario comparte de manera activa y voluntaria: respuestas a encuestas, preferencias declaradas e intenciones explícitas. Ambos son complementarios, pero el zero party data elimina ambigüedades de interpretación porque el usuario mismo declara su intención.
¿Por qué el fin de las cookies de terceros afecta la estrategia de datos propios?
La desaparición progresiva de cookies de terceros y el avance de controles de privacidad reducen el mecanismo histórico de tracking cross-site que permitía construir audiencias sin datos propios. Los equipos que no desarrollaron una infraestructura de captura en paralelo están viendo cómo sus modelos de audiencia pierden precisión sin un sustituto claro. Google mantiene documentación activa sobre third-party cookies y sus alternativas de medición.
¿Puedo activar mis datos propios dentro de plataformas como Meta o Google?
Sí. Una estrategia madura de first party data no excluye a las plataformas, las usa de manera diferente. Customer Match en Google y Custom Audiences en Meta permiten activar datos propios dentro de sus ecosistemas, recuperando control sobre la segmentación sin depender únicamente de sus datos internos.
¿Cada cuánto tiempo se vuelve obsoleta una base de datos propia?
Una base de datos propia no caduca si tiene una estrategia de enriquecimiento continuo. El problema no es la edad del dato sino la ausencia de captura activa. Sin actualización periódica, pierde relevancia en 12 a 18 meses dependiendo del sector y la frecuencia de compra.